Overcoming performance limits with unrivaled technology
Multi GPU acceleration
GPUDirect RDMA - GPU acceleration, a core technology in artificial intelligence
infrastructure management, is a technology that virtualizes multiple GPU servers
and controls the network path so that communication between servers occurs
directly between GPUs without GPU control.
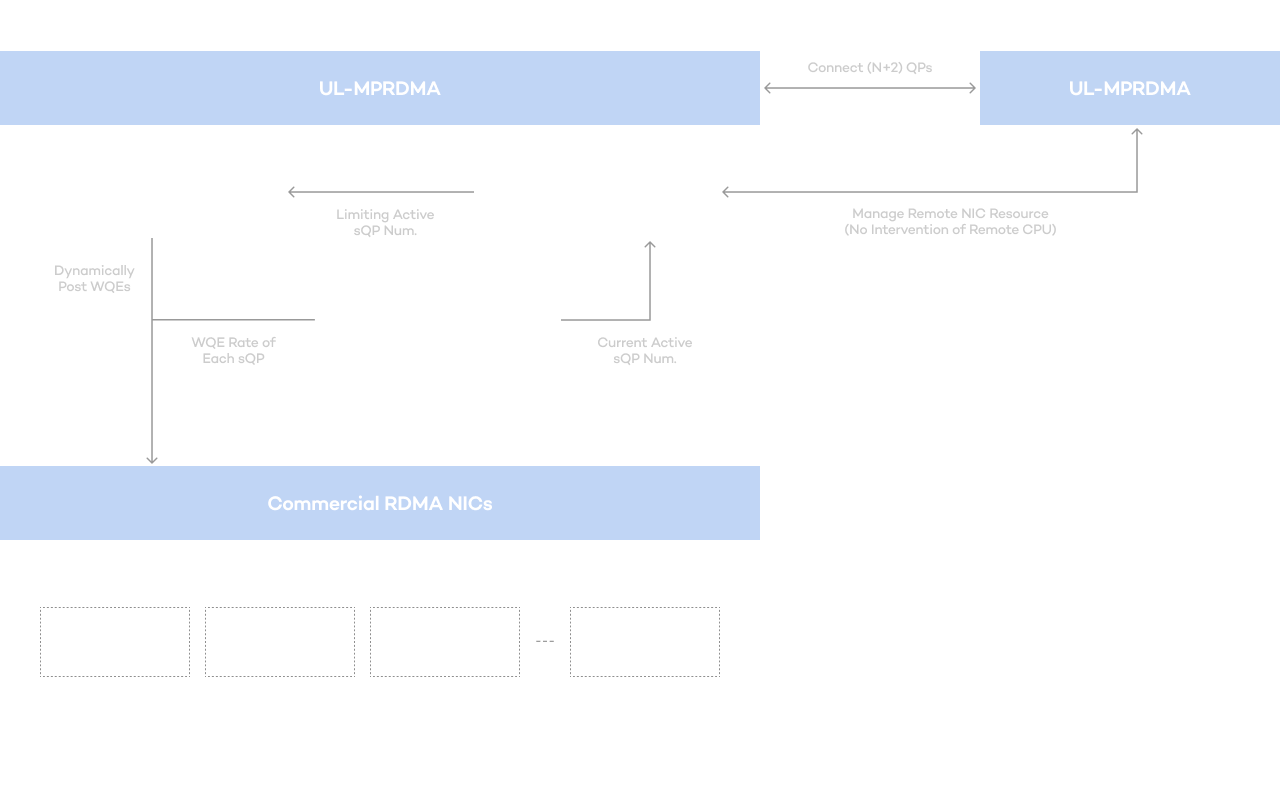
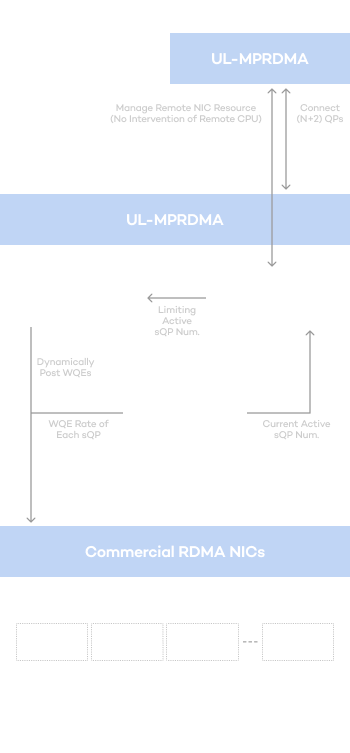
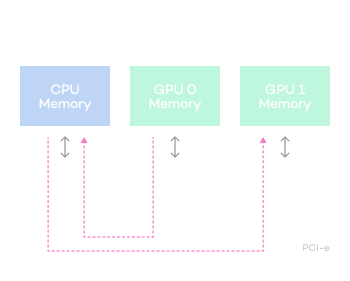
Limitations of existing GPUDirect RDMA
Jonathan®'s overwhelming efficiency (MPU) through a differentiated approach
- Related paper published in SCI(E) level journal in July 2021 and applied for domestic patent
- Expanded and applied technical papers related to this work were submitted to ATC, a top-tier society in the Network/System field, in January 2024.
Multi-GPU high-speed communication
technology and distributed learning
Efficiency innovation created by differentiated multi-path transmission technology and resource sharing technology
The deep learning model design process takes a lot of time, so accelerating the learning process of artificial intelligence models is very important. One of the essential technologies for shortening the learning time of these deep learning models is distributed learning.
ACRYL's GPUDirect technology, maximizes the performance of distributed learning by minimizing the load of data exchange between GPUs or servers (performing zero-copy data transfer) when performing distributed learning based on multiple GPUs and servers.
Jonathan® supports GPUDirect P2P and RDMA and enables users to conveniently use high-performance distributed learning by enabling the functions with just a click.It also supports distributed learning of artificial intelligence models using multiple GPUs in an automated manner without user intervention, and has excellent performance that is linearly proportional to the number of GPUs.
By applying differentiated multi-path transmission technology and resource sharing technology related to GPUDirect RDMA, completed through years of research, it provides performance and efficiency that cannot be experienced in other platforms.
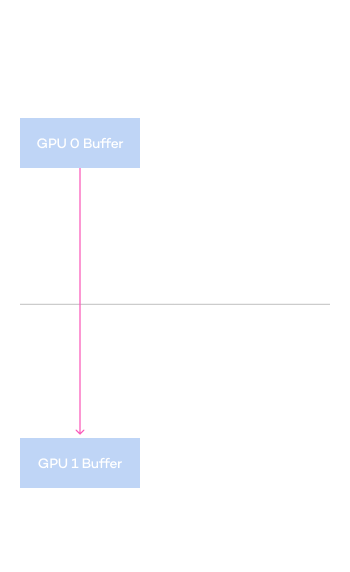
Comparison of accelerated communication speeds
between GPUs within the same server
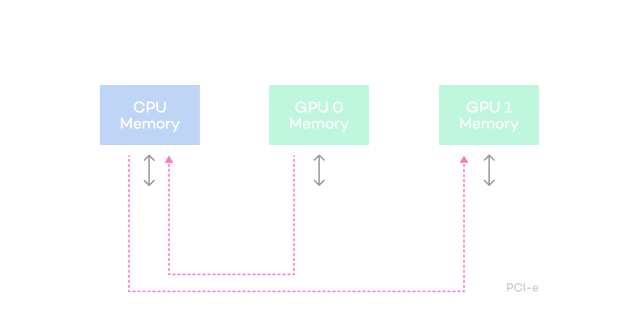
- Latency
(us) - Dev.0
Dev.1 - Dev.1
Dev.0
- Disabled
- 14.31
- 14.71
- Enabled
- 1.68
- 1.68
- Speed-up
- 8.52 times
- 8.70 times
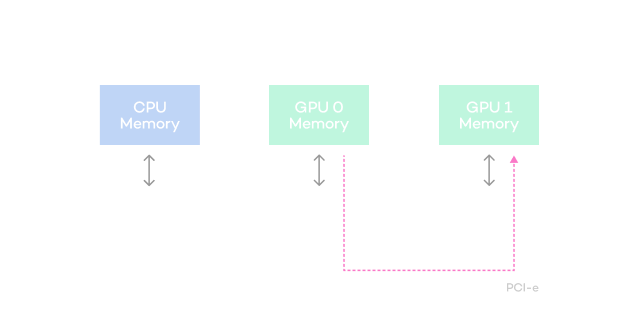
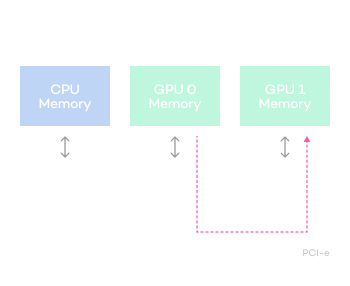
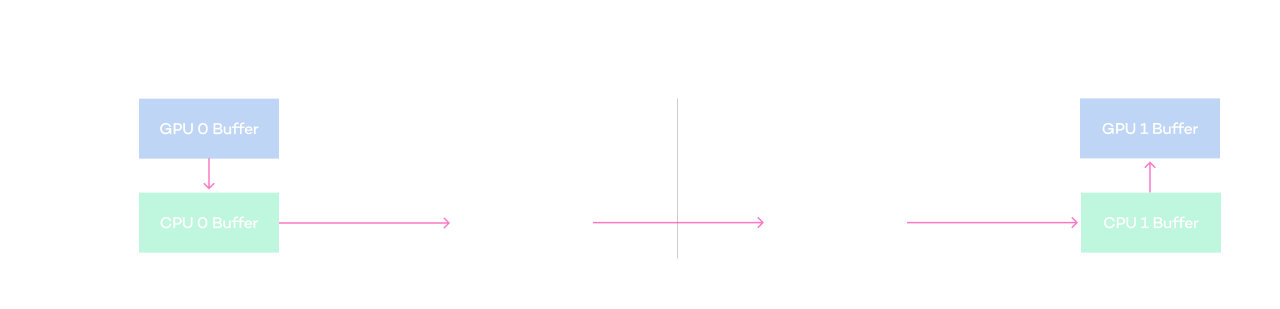
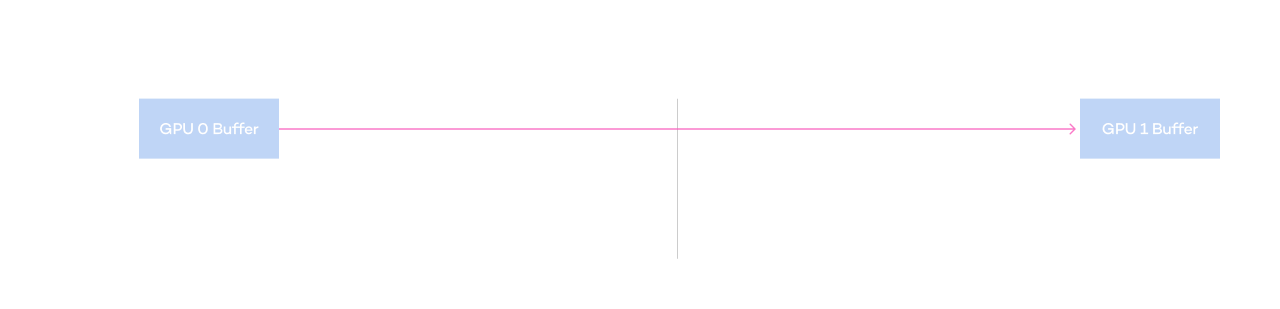
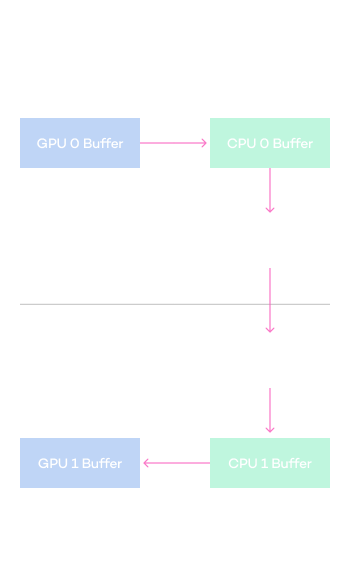
Diagram of accelerated communication function
between GPUs of heterogeneous servers
Federated Learning
A new paradigm of data collaboration using AI
In general, the larger the amount of data, the better the performance of the AI model, so securing large amounts of data is important to build high-performance AI. However, if data is distributed across companies/institutions and sharing and integration are limited, there are bound to be limits to improving the performance of artificial intelligence models. In particular, in certain domains such as medicine and finance, it is difficult to export the data, which creates limitations in improving the performance of related AI models.
The federated learning of ACRYL, a global AI specialist company, is a technology that transmits only the learning information of artificial intelligence models trained by each institution to the central GPU server and synthesizes them into a single artificial intelligence learning model.
Therefore, collaboration between organizations with sensitive data including personal information and collaboration between companies with internal information as an asset is possible because the AI model being trained is shared and cooperated without data movement.
ACRYL's federated learning technology can be used to improve model performance without data sharing not only between institutions (cross-silo) where data sharing is difficult, but also between devices (cross-device), especially in the medical field where data sharing is difficult. It can be actively used when introducing artificial intelligence technology in public institutions.

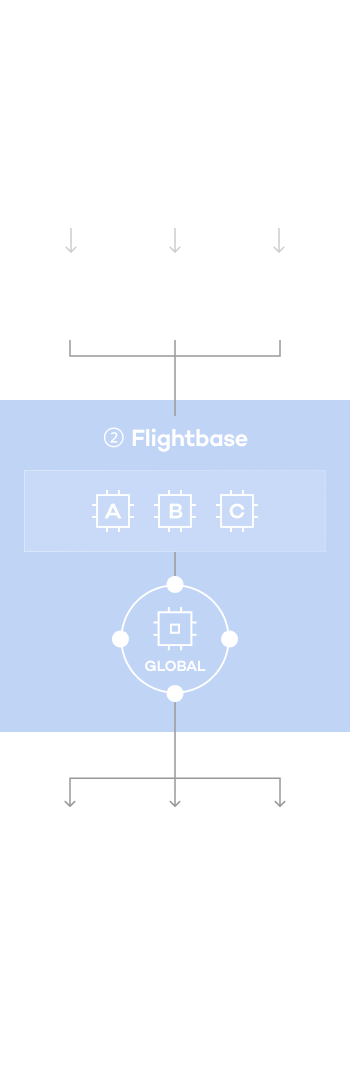
- Once the federated learning round begins, artificial intelligence Model is trained using the data sets within each institution.
- Local AI after training reflects characteristics of each organization's unique training data set.
- Local artificial intelligence models are sent to the central server, and actual data is not exported to the outside.
- Each local model gathered on the central server goes through a synthesis process to create a single global artificial intelligence that reflects all data characteristics of each organization.
- Sends the synthesized global AI from the central server back to each organization.
- Complete construction of AI trained with various institutions' data in one place, without actually exporting data.